New Chunking Method for RAG-Systems
Enhanced Document Splitting

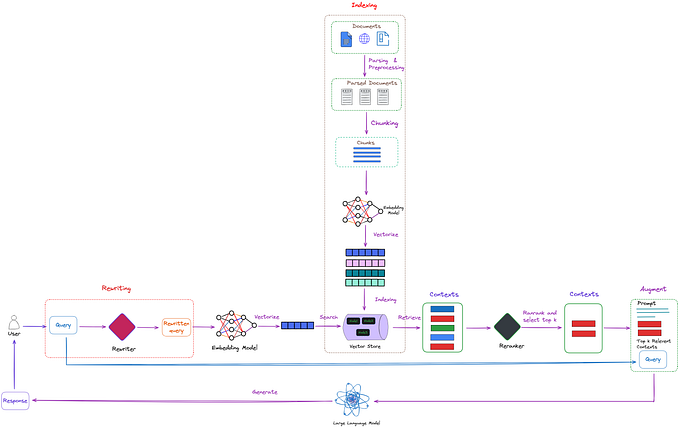
Dividing large documents into smaller parts is an essential but critical factor that influences the performance of Retrieval Augmented Generation (RAG) systems. Frameworks for developing RAG systems usually offer several options to choose from. In this article, I want to introduce a new option that attempts to recognize a change of topic with the help of sentence embeddings when subdividing the documents to carry out the subdivision at these points. This lays the foundation that in the embedding step of an RAG system, vectors can be found for the text parts that encode a topic and are not a mixture of several. We have presented this method in a paper in the context of topic modeling, but it is also suitable for use in RAG systems.
RAG-Systems
A Retrieval-Augmented Generation (RAG) system is a machine learning model that combines retrieval-based and generation-based approaches to improve the quality and relevance of its outputs. It first retrieves relevant documents or information from a large dataset based on the input query. Then, it uses a generation model, such as a transformer-based language model, to generate a coherent and contextually appropriate response or content using the retrieved information. This hybrid approach enhances the model’s ability to provide accurate and informative responses, especially in complex or knowledge-intensive tasks.
Other Splitting Options
Before we examine the procedure in more detail, I would like to present some other standard options for document splitting. I will use the widely used Langchain framework to show examples.
LangChain is a robust framework designed to assist with various natural language processing (NLP) tasks, mainly focusing on applying large language models. One of its essential functionalities is document splitting, which enables users to break down large documents into smaller, manageable chunks. Below are the key features and examples of document splitting in LangChain:
Key Features of Document Splitting in LangChain
- Recursive Character Text Splitter: This method splits documents by recursively dividing the text based on characters, ensuring each chunk is below a specified length. This is particularly useful for documents with natural paragraph or sentence breaks.
- Token Splitter: This method splits the document using tokens. It is beneficial when working with language models with token limits, ensuring each chunk fits the model’s constraints.
- Sentence Splitter: This method splits documents at sentence boundaries. It is ideal for maintaining the contextual integrity of the text, as sentences usually represent complete thoughts.
- Regex Splitter: This method uses regular expressions to define custom split points. It offers the highest flexibility, allowing users to split documents based on patterns specific to their use case.
- Markdown Splitter: This method is tailored for markdown documents. It splits the text based on markdown-specific elements like headings, lists, and code blocks.
Examples of Document Splitting in LangChain
1. Recursive Character Text Splitter
from langchain.text_splitter import RecursiveCharacterTextSplitter
text = "Your long document text goes here..."
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
chunks = splitter.split_text(text)
for chunk in chunks:
print(chunk)2. Token Splitter
from langchain.text_splitter import TokenSplitter
text = "Your long document text goes here..."
splitter = TokenSplitter(max_tokens=512)
chunks = splitter.split_text(text)
for chunk in chunks:
print(chunk)3. Sentence Splitter
from langchain.text_splitter import SentenceSplitter
text = "Your long document text goes here..."
splitter = SentenceSplitter(max_length=5)
chunks = splitter.split_text(text)
for chunk in chunks:
print(chunk)4. Regex Splitter
from langchain.text_splitter import RegexSplitter
text = "Your long document text goes here..."
splitter = RegexSplitter(pattern=r'\n\n+')
chunks = splitter.split_text(text)
for chunk in chunks:
print(chunk)5. Markdown Splitter
from langchain.text_splitter import MarkdownSplitter
text = "Your long markdown document goes here..."
splitter = MarkdownSplitter()
chunks = splitter.split_text(text)
for chunk in chunks:
print(chunk)Introducing a New Approach
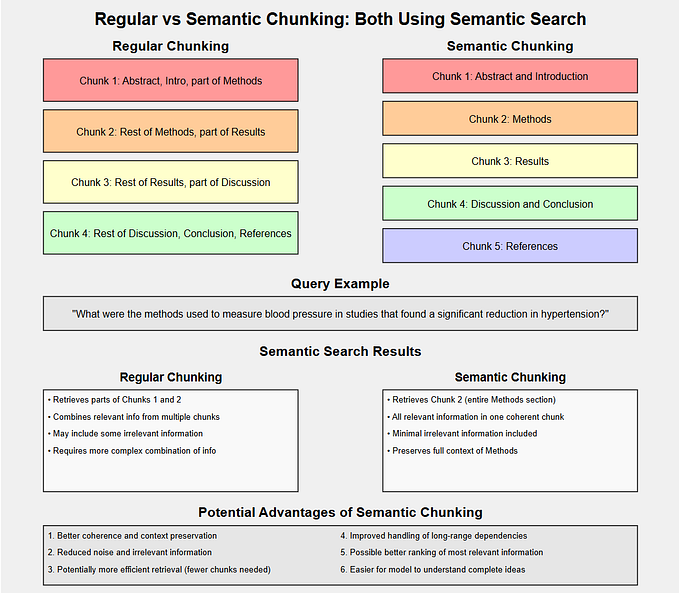
Segmenting large-scale documents into coherent topic-based sections in digital content analysis is a significant challenge. Traditional methods, such as those described above, often fail to accurately detect the subtle junctures where topics shift. In a paper presented at the International Conference on Artificial Intelligence, Computer, Data Sciences, and Applications (ACDSA 2024), we propose an innovative approach to tackle this issue.
The Core Challenge
Large documents, such as academic papers, lengthy reports, and detailed articles, are complex and contain multiple topics. Conventional segmentation techniques, ranging from simple rule-based methods to advanced machine learning algorithms, struggle to identify precise points of topic transitions. These methods often miss subtle transitions or falsely identify them, leading to fragmented or overlapping sections.
Our method leverages the power of sentence embeddings to enhance the segmentation process. The approach quantitatively measures their similarity by utilizing Sentence-BERT (SBERT) to generate embeddings for individual sentences. As topics shift, these embeddings reflect changes in the vector space, indicating potential topic transitions.
Look at each step of the approach:
1. Using Sentence Embeddings
Generating Embeddings:
- The method employs Sentence-BERT (SBERT) to generate embeddings for individual sentences. SBERT creates dense vector representations of sentences that encapsulate their semantic content.
- These embeddings are then compared to identify coherence between consecutive sentences.
Similarity Calculation:
- The similarity between sentences is measured using cosine similarity or other distance measures like Manhattan or Euclidean distance.
- The idea is that sentences within the same topic will have similar embeddings, while sentences from different issues will show a drop in similarity.
2. Calculating Gap Scores
Defining a Parameter n:
- A parameter n is set, specifying the number of sentences to be compared. For instance, if n=2, two consecutive sentences are compared with the next pair.
- The choice of n affects the context length considered in the comparison, balancing the need to capture detailed transitions with computational efficiency.
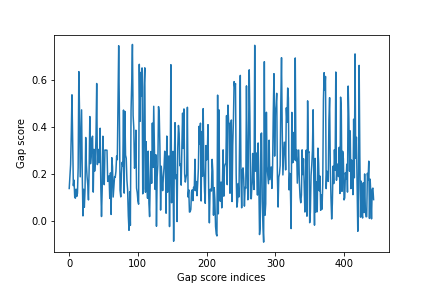
Computing Cosine Similarity:
- For each position in the document, the algorithm extracts n sentences before and after the current position.
- It then calculates the cosine similarity between the embeddings of these sequences, termed ‘gap scores.’
- These gap scores are stored in a list for further processing.
3. Smoothing
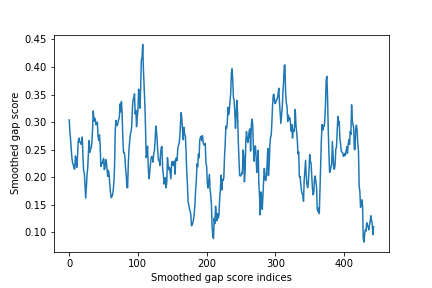
Addressing Noise:
- The raw gap scores can be noisy due to minor variations in the text. To counteract this, a smoothing algorithm is applied.
- Smoothing involves averaging the gap scores over a window defined by a parameter k.
Choosing the Window Size k:
- The window size k determines the extent of smoothing. Larger k values lead to more smoothing, reducing noise but potentially missing subtle transitions. Smaller k values retain more detail but may introduce noise.
- The smoothed gap scores provide a more unambiguous indication of where topic transitions occur.
4. Boundary Detection
Identifying Local Minima:
- The smoothed gap scores are analyzed to identify local minima and potential points of topic transitions.
- Depth scores are computed for each local minimum by summing the differences between the local minimum and the values before and after.
Setting a Threshold c:
- A threshold parameter c is used to determine significant boundaries. A higher c value results in fewer, more significant segments, while a lower c value results in more, smaller segments.
- Boundaries exceeding the mean depth score by more than c times the standard deviation are considered valid segmentation points.
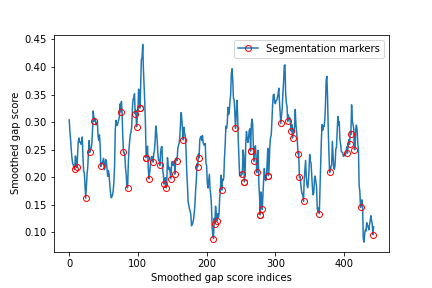
5. Clustering Segments
Handling Repeated Topics:
- Longer documents may revisit similar topics at different points. To address this, the algorithm clusters segments with analogous content.
- This involves converting segments into embeddings and using clustering techniques to merge similar segments.
Reducing Redundancy:
- Clustering helps reduce redundancy by ensuring each topic is uniquely represented, enhancing the overall coherence and accuracy of the segmentation.
Algorithm Pseudocode
Gap Score Calculation:

Gap Score Smoothing:
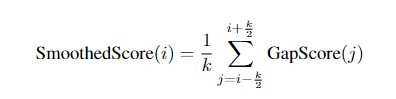
Boundary Detection:
- Depth scores are calculated for each local minimum.
- Thresholding is applied using the parameter c to determine significant segmentation points.
Future Directions
The study outlines several areas for further research to enhance this method:
- Automatic Parameter Optimization: Using machine learning techniques to adjust parameters dynamically.
- More extensive Dataset Trials: Testing the method on diverse, large datasets.
- Real-time Segmentation: Exploring real-time applications for dynamic documents.
- Model Improvements: Integrating newer transformer models.
- Multilingual Segmentation: Applying the method to different languages using multilingual SBERT.
- Hierarchical Segmentation: Investigating segmentation at multiple levels for detailed document analysis.
- User Interface Development: Creating interactive tools for more effortlessly adjusting segmentation results.
- Integration with NLP Tasks: Combining the algorithm with other natural language processing tasks.
Conclusion
Our method presents a sophisticated approach to document segmentation, combining traditional principles with cutting-edge sentence embeddings. By leveraging SBERT and advanced smoothing and clustering techniques, the process offers a robust and efficient solution for accurate topic modeling in large documents.
Visit us at DataDrivenInvestor.com
Subscribe to DDIntel here.
Featured Article:
Join our creator ecosystem here.
DDI Official Telegram Channel: https://t.me/+tafUp6ecEys4YjQ1